Параллельные вычисления
Мы говорили об архитектуре вычислительных комплексов, способных обеспечить параллельное выполнение программ. Но архитектура комплекса — это лишь одно из требований, необходимых для реализации подлинного параллелизма. Другие два требования связаны с требованиями к операционной системе и к самой программе. Не всякую программу можно распараллелить независимо о того, на каком суперкомпьютерном комплексе она будет выполняться. В следующих главах мы подробнее поговорим о средствах операционной системы, обеспечивающих параллелизм вычислений, и о параллельных алгоритмах. Сейчас же рассмотрим некоторую модель параллельного выполнения, где главным действующим лицом будет программа .
Параллельные вычисления становятся одним из магистральных направлений развития информационных технологий. Можно указать на две причины, определяющие важность этого направления. Первая состоит в том, что стратегически важные для развития государства задачи могут быть решены только с применением суперкомпьютеров, обладающих сотнями тысяч процессоров, которые нужно заставить работать одновременно. Вторая причина связана с другим полюсом компьютерной техники, на котором находятся обычные компьютеры, ориентированные на массового пользователя. И эта техника становится многоядерной, и ее требуется эффективно использовать, так что параллельные вычисления требуются и здесь.
Для поддержки параллельных вычислений сделано достаточно много, начиная от архитектуры вычислительных систем, операционных систем, языков программирования до разработки специальных параллельных алгоритмов. Тем не менее, для программиста, решающего сложную задачу, построение и отладка эффективной параллельной программы все еще остается не простым занятием.
Рассмотрим одну из моделей параллельного вычисления. Для этой модели мы хотим получить оценки времени выполнения программы одним процессором — , конечным числом процессоров — , и для идеализированного случая, когда число процессоров не ограничивается — » />.
Рассмотрим программу P , состоящую из n модулей:
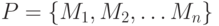
Множество модулей разобьём на k уровней. К уровню i отнесем те модули, для начала работы которых требуется завершение работы модулей верхних уровней, из которых хотя бы один принадлежит уровню i — 1. Модуль уровня i с номером k будем обозначать как .
Модули, принадлежащие уровню 1, имеют все необходимые данные, полученные от внешних источников. Они не требуют завершения работы других модулей и в принципе могут выполняться параллельно, будучи запущенными в начальный момент выполнения программы.
Свяжем с программой P ориентированный граф зависимостей модулей. Граф не содержит циклов и отражает разбиение модулей на уровни. Модули являются вершинами графа, а дуги отражают зависимости между модулями. Дуга ведет от модуля к модулю , если для начала выполнения модуля требуется завершение работы модуля . В узлах графа содержится информация об ожидаемом времени выполнения модуля, где время измеряется в некоторых условных единицах. На Рис. 1.1 показан пример графа зависимостей:
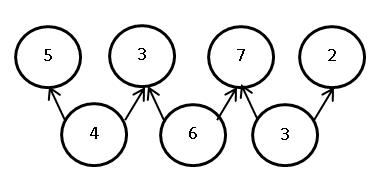
Обозначим через — время, требуемое для выполнения программы P одним процессором, — p процессорами, >» /> — время, требуемое в случае, когда число процессоров неограниченно. В последнем случае достаточно n процессоров, по числу модулей нашей программы.
Предполагается, что все эти характеристики рассчитываются при соблюдении двух условий:
- Выполняются зависимости между модулями, заданные графом зависимостей.
- Характеристики вычислены для оптимального расписания работы процессоров.
В случае одного процессора достаточно выполнение только первого условия. Обычно предполагается естественный порядок выполнения модулей, — последовательное выполнение модулей одного уровня, затем переход к выполнению модулей следующего уровня.
Для случая неограниченного числа процессоров оптимальным является такое расписание, когда каждый модуль начинает выполняться, как только завершены все модули, необходимые для его работы.
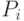
Для случая p процессоров можно распределить модули по процессорам, задав для каждого процессора множество модулей, выполняемых этим процессором:
Читать статью Лучшие кулеры для процессора - Рейтинг 2022 (ТОП 12)

Задача составления оптимального расписания относится к сложным задачам. На практике для программ большого размера не удается явно вычислить значение . По этой причине несомненный интерес представляет получение оценок для .
Для введенных характеристик выполняется естественное соотношение:
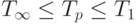 ( 1.1) ( 1.1) |
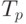
Нас будет интересовать получение более точных оценок для .
Рассмотрим вначале упрощенную ситуацию, предположив, что время выполнения всех модулей одинаково и равно t . Нетрудно видеть, что
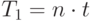 |
( 1.2) |
Действительно, один процессор должен выполнить все модули программы, проходя, например, последовательно один уровень за другим.
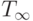
 ( 1.3) ( 1.3) |
Действительно, пусть на первом уровне модулей. У них есть все необходимые данные, и они могут выполняться параллельно. Поскольку число процессоров неограниченно, то запустив каждый модуль на одном из имеющихся процессоров, за время t завершим выполнение модулей первого уровня. Пусть за время завершено выполнение всех модулей всех уровней от первого до i -го. Тогда возможно параллельно выполнять модули следующего i + 1 -го уровня, число которых равно » />. Процессоров у нас хватает, поэтому на завершение всех модулей этого уровня потребуется t времени, и общее время выполнения равно , что по индукции доказывает справедливость формулы (3).
Для времени получим оценки сверху и снизу. Понятно, что p процессоров, начав одновременно работать, могут выполнить вычисление модулей уровня i за время
right rceil cdot t» />, где обозначает минимальное целое, большее или равное x . Два процессора смогут выполнить пять модулей уровня 1 за время . Отсюда следует, что общее время работы дается формулой:
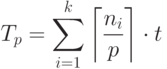 ( 1.4) ( 1.4) |

Поскольку , то
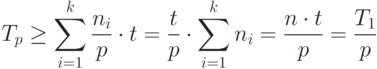 ( 1.5) ( 1.5) |
Формула (5) дает нижнюю оценку времени выполнения работы p процессорами.
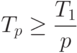 ( 1.6) ( 1.6) |
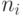
Если на каждом уровне число модулей кратно p , то оценка достижима. В лучшем случае p процессоров могут сократить время выполнения программы в p раз в сравнении со временем, требуемом для выполнения этой работы одним процессором.
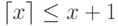
Получим теперь оценку сверху. Поскольку , то
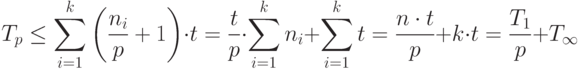 ( 1.7) ( 1.7) |
Объединяя (6) и (7), получим
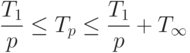 ( 1.8) ( 1.8) |
Оценки (8) для случая, когда время выполнения всех модулей одинаково, известны [5].
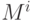
Рассмотрим теперь более интересный для практики случай, когда модули программы для своего выполнения требуют разного времени. Пусть — множество модулей уровня i :
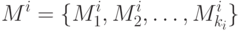 ( 1.9) ( 1.9) |
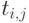
И в этом случае нетрудно рассчитать время — время, требуемое на выполнение всей работы одним процессором:
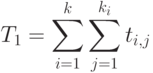 ( 1.10) ( 1.10) |
Как рассчитать время >» /> в этой ситуации, когда мы располагаем неограниченным числом процессоров? Введем для каждого модуля время окончания его работы — . Это время будем рассчитывать по следующей формуле:
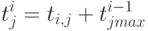 ( 1.11) ( 1.11) |

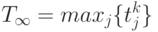 ( 1.12) ( 1.12) |

- Управление процессором (Processor management)
- Управление памятью (Memory management)
- Управление устройством (Device management)
- Управление накопителем (Storage management)
- Интерфейс приложения (Application interface)
- Интерфейс пользователя (User interface)
Читатели могут отметить, что современная операционная система умеет много такого, что не вмещается ни в одну из этих шести групп. И будут правы. Разработчики операционных систем оснащают их множеством вспомогательных утилит и дополнительных функций. Но эти шесть категорий, которые нам предстоит рассмотреть, составляют саму суть того, что положено делать операционной системе.
Управление процессором

Управление процессором компьютера сводится к решению двух, теснейшим образом связанных между собою проблем:
- Обеспечение каждого программного процесса и приложения достаточным для корректного функционирования временем процессора
- Использование циклов процессора в том объеме, который реально необходим для работы
Основной единицей программного обеспечения, которой операционная система выделяет процессорное время, является процесс или поток (тред). Это зависит от конкретной операционной системы.
Можно даже сказать, что операционная система склонна воспринимать процесс в качестве приложения. Но это упрощение не описывает всей сложности взаимодействия процессов с операционной системой и аппаратным обеспечением компьютера. Процессом является любое приложение: текстовый редактор, электронная таблица или игра. Но приложение может вести к запуску дополнительных процессов, обеспечивающих взаимодействие с устройствами или другими компьютерами.
Когда операционная система работает, в ней запущено множество процессов, которые даже не дают вам знать о своем существовании. Например, в Windows XP или UNIX работают десятки фоновых процессов. В список их задач входят: обеспечение работы сети, управление памятью компьютера и его дисками, проверка системы на вирусы. Разумеется, этим круг их задач не исчерпывается.
Процессом называется программное обеспечение, выполняющее некую работу. Каждый процесс должен кем-то или чем-то контролироваться: операционной системой, другим приложением или непосредственно пользователем.
Операционная система управляет скорее процессами, чем приложениями и именно их она ставит в расписание центрального процессора. В однозадачных операционных системах это расписание линейно. Операционная система позволяет приложению запуститься, прерывая его выполнение только на те промежутки времени, которые требуются пользователю на ввод данных или другие прерывания.
Прерываниями называют специальные сигналы, исходящие от аппаратного и программного обеспечения. Они происходят тогда, когда та или иная часть компьютера неожиданно требует к себе внимания со стороны центрального процессора. Порой операционная система определяет приоритет процессов и маскирует некоторые прерывания. То есть она игнорирует прерывания от некоторых источников, позволяя процессору сначала справиться с уже выполняемой им работой.
Но некоторые прерывания крайне важны и не игнорируются. Речь идет о проблемах памяти и ошибках. Эти прерывания называют немаскируемыми и они обрабатываются немедленно, вне зависимости от того, над какими задачами в данный момент работает процессор. В качестве наиболее яркого (но, разумеется, не единственного) примера немаскируемого прерывания можно привести прерывание по прекращению подачи питания. Нетрудно понять, что такое прерывание всегда ведет к прекращению работы процессора по весьма уважительной причине.
Прерывания усложняют работу даже однозадачной операционной системы. Каждодневный труд многозадачной операционной системы еще сложнее. Сегодня операционная система должна выполнять приложения таким образом, чтобы для вас это выглядело в качестве событий, происходящих одновременно. Современные многоядерные процессоры и многопроцессорные компьютеры, разумеется, очень работоспособны, но каждое ядро процессора до сих пор может выполнять лишь одну задачу в один момент времени.
Чтобы создавалось впечатление одновременно происходящих событий, операционной системе приходится переключаться между процессами тысячи раз за одну только секунду. Теперь рассмотрим то, как все это происходит в реальности:
- Процесс занимает определенный объем в оперативной памяти (ОЗУ, RAM). Он также может использовать регистры, стеки и очереди в рамках памяти процессора и операционной системы
- Когда два процесса выполняются одновременно в многозадачном режиме, операционная система выделяет одной программе определенное количество исполнительных циклов процессора
- После выполнения этой последовательности циклов, операционная система копирует состояние всех регистров, стеков и очередей, использованных в ходе работы над выполнением процесса и отмечает точку, в которой выполнение процесса было приостановлено
- Затем загружает все регистры, стеки и очереди, используемые вторым процессом и позволяет процессору уделить ему некоторое количество циклов
- Когда все это уже произошло, она вновь копирует состояние всех регистров, стеков и очередей, использованных второй программой и в очередной раз загружает первую программу
Управляющий блок процесса

Вся информация, необходимая для отслеживания процесса, содержится в пакете данных, именуемом управляющим блоком процесса (process control block). Таким образом состояние процесса не теряется при переключении между задачами. В общем случае, управляющий блок процесса содержит:
- Номер-идентификатор (ID), идентифицирующий данный процесс
- Указатели и положения программы и ее данных на момент последней обработки процесса
- Контент регистра
- Состояния различных признаков и переключателей
- Список открытых процессом файлов
- Приоритет процесса
- Статус всех необходимых данному процессу устройств ввода и вывода
Каждый процесс характеризуется связанным с ним статусом (состоянием). Многие процессы в определенных ситуациях не требуют времени центрального процессора. К примеру, процесс может находиться в состоянии ожидания нажатия пользователем клавиши. В этом состоянии процесс называют приостановленным (suspended). Когда поступает информация о нажатии клавиши, операционная система меняет его статус. В данном конкретном примере речь идет о том, что статус ожидания сменяется статусом исполнения. Для продолжения выполнения процесса используется информация из его управляющего блока.
Подкачка процессов не требует непосредственного вмешательства пользователя. Каждый процесс получает в свое распоряжение достаточно циклов процессора, чтобы выполнить свою задачу за разумный промежуток времени. Проблемы наступают, когда пользователь начинает одновременно работать со слишком большим числом процессов. Операционная система и сама требует определенного количества циклов процессора на сохранение всех регистров и очередей и переключение между задачами. Операционная система не идеальна, и может случиться так, что она начнет использовать большую часть отведенных ей циклов процессора на переключение между процессами, а не на их запуск. Это называется пробуксовкой и обычно требует вмешательства пользователя. Ему необходимо завершить некоторые процессы и навести порядок в работе системы.
Все рассмотренное нами выше касается тех случаев, когда компьютер располагает всего одним процессором. На машинах, располагающих двумя и более процессорами, операционной системе приходится распределять между ними свою рабочую нагрузку. И при этом стараться поддержать баланс между потребностями процессов и количеством доступных циклов разных процессоров. Асимметричные операционные системы выделяют один из процессоров под свои собственные нужды, а процессы приложений распределяют между остальными. Симметричные операционные системы распределяют свои нужды между несколькими процессорами даже в тех случаях, если никаких других задач больше не запущено.
В дальнейшем нам предстоит поговорить еще о пяти категориях задач, которые постоянно «держит в уме» самая обычная операционная система любого компьютера.
Источник https://intuit.ru/studies/courses/10554/1092/lecture/27087?page=2
Источник https://www.cyberforum.ru/blogs/220983/blog2258.html
Источник https://hi-news.ru/software/chtivo-kak-operacionnaya-sistema-raspredelyaet-vremya-processora.html