Цикл выполнения команды
Программа состоит из машинных команд. Программа загружается в оперативную память компьютера. Затем программа начинает выполняться, то есть процессор выполняет машинные команды в той последовательности, в какой они записаны в программе.
Для того чтобы процессор знал, какую команду нужно выполнять в определённый момент, существует счётчик команд – специальный регистр, в котором хранится адрес команды, которая должна быть выполнена после выполнения текущей команды. То есть при запуске программы в этом регистре хранится адрес первой команды. В процессорах Intel в качестве счётчика команд (его ещё называют указатель команды) используется регистр EIP (или IP в 16-разрядных программах).
Счётчик команд работает со сверхоперативной памятью, которая находится внутри процессора. Эта память носит название очередь команд, куда помещается одна или несколько команд непосредственно перед их выполнением. То есть в счётчике команд хранится адрес команды в очереди команд, а не адрес оперативной памяти.
Порядок работы процессора при выполнении программы
2.1. Процессор.
Самый основной элемент компьютера, это, конечно, процессор. Давайте подробней его рассмотрим. Упрощённая структура процессора (рис. 4):

Рис. 4. Упрощённая структура процессора
Основные элементы процессора:
· Регистры – это специальные ячейки памяти, физически расположенные внутри процессора. В отличие от ОЗУ, где для обращения к данным требуется использовать шину адреса, к регистрам процессор может обращаться напрямую. Это существенно ускорят работу с данными.
· Арифметико-логическое устройство выполняет арифметические операции, такие как сложение, вычитание, а также логические операции.
· Блок управления определяет последовательность микрокоманд, выполняемых при обработке машинных кодов (команд).
· Тактовый генератор , или генератор тактовых импульсов, задаёт рабочую частоту процессора.
2.2. Режимы работы процессора.
Процессор архитектуры x86 может работать в одном из пяти режимов и переключаться между ними очень быстро:
1. Реальный (незащищенный) режим (real address mode) — режим, в котором работал процессор 8086. В современных процессорах этот режим поддерживается в основном для совместимости с древним программным обеспечением (DOS-программами).
2. Защищенный режим (protected mode) — режим, который впервые был реализован в 80286 процессоре. Все современные операционные системы (Windows, Linux и пр.) работают в защищенном режиме. Программы реального режима не могут функционировать в защищенном режиме.
3. Режим виртуального процессора 8086 (virtual-8086 mode, V86) — в этот режим можно перейти только из защищенного режима. Служит для обеспечения функционирования программ реального режима, причем дает возможность одновременной работы нескольких таких программ, что в реальном режиме невозможно. Режим V86 предоставляет аппаратные средства для формирования виртуальной машины, эмулирующей процессор8086. Виртуальная машина формируется программными средствами операционной системы. В Windows такая виртуальная машина называется VDM (Virtual DOS Machine — виртуальная машина DOS). VDM перехватывает и обрабатывает системные вызовы от работающих DOS-приложений.
4. Нереальный режим (unreal mode, он же big real mode) — аналогичен реальному режиму, только позволяет получать доступ ко всей физической памяти, что невозможно в реальном режиме.
5. Режим системного управления System Management Mode (SMM) используется в служебных и отладочных целях.
При загрузке компьютера процессор всегда находится в реальном режиме, в этом режиме работали первые операционные системы, например MS-DOS, однако современные операционные системы, такие как Windows и Linux переводят процессор в защищенный режим. Вам, наверное, интересно, что защищает процессор в защищенном режиме? В защищенном режиме процессор защищает выполняемые программы в памяти от взаимного влияния (умышленно или по ошибке) друг на друга, что легко может произойти в реальном режиме. Поэтому защищенный режим и назвали защищенным.
2.3. Регистры процессора (программная модель процессора).
Для понимания работы команд ассемблера необходимо четко представлять, как выполняется адресация данных, какие регистры процессора и как могут использоваться при выполнении инструкций. Рассмотрим базовую программную модель процессоров Intel 80386, в которую входят:
· 8 регистров общего назначения, служащих для хранения данных и указателей;
· регистры сегментов — они хранят 6 селекторов сегментов;
· регистр управления и контроля EFLAGS, который позволяет управлять состоянием выполнения программы и состоянием (на уровне приложения) процессора;
· регистр-указатель EIP выполняемой следующей инструкции процессора;
· система команд (инструкций) процессора;
· режимы адресации данных в командах процессора.
Начнем с описания базовых регистров процессора Intel 80386.
Базовые регистры процессора Intel 80386 являются основой для разработки программ и позволяют решать основные задачи по обработке данных. Все они показаны на рис. 5.

Рис. 5. Базовые регистры процессора Intel 80386
Среди базового набора регистров выделим отдельные группы и рассмотрим их назначение.
2.4. Регистры общего назначения.
32-битные регистры ЕАХ (аккумулятор), ЕВХ (база), ЕСХ (счетчик), EDX (регистр данных) могут использоваться без ограничений для любых целей – временного хранения данных, аргументов или результатов различных операций. Названия регистров происходят от того, что некоторые команды применяют их специальным образом: так, аккумулятор часто необходим для хранения результата действий, выполняемых над двумя операндами, регистр данных в этих случаях получает старшую часть результата, если он не умещается в аккумулятор, регистр-счетчик работает как счетчик в циклах и строковых операциях, а регистр-база – при так называемой адресации по базе. Младшие 16 бит каждого из этих регистров применяются как самостоятельные регистры с именами АХ, ВХ, СХ, DX. На самом деле в процессорах 8086 – 80286 все регистры были 16-битными и назывались именно так, а 32-битные ЕАХ – EDX появились с введением 32-битной архитектуры в 80386. Кроме этого, отдельные байты в 16-битных регистрах АХ – DX тоже могут использоваться как 8-битные регистры и иметь свои имена. Старшие байты этих регистров называются АН, ВН, СН, DH, а младшие — AL, BL, CL, DL (см. рис.4.1).
Остальные четыре регистра – ESI (индекс источника), EDI (индекс приемника), ЕВР (указатель базы), ESP (указатель стека) – имеют более конкретное назначение и применяются для хранения всевозможных временных переменных. Регистры ESI и EDI необходимы в строковых операциях, ЕВР и ESP – при работе со стеком. Так же как и в случае с регистрами ЕАХ — EDX, младшие половины этих четырех регистров называются SI, DI, BP и SP соответственно, и в процессорах до 80386 только они и присутствовали.
2.5. Сегментные регистры.
При использовании сегментированных моделей памяти для формирования любого адреса нужны два числа – адрес начала сегмента и смещение искомого байта относительно этого начала (в бессегментной модели памяти flat адреса начал всех сегментов равны). Операционные системы (кроме DOS) могут размещать сегменты, с которыми работает программа пользователя, в разных местах памяти и даже временно записывать их на диск, если памяти не хватает. Так как сегменты способны оказаться где угодно, программа обращается к ним, применяя вместо настоящего адреса начала сегмента 16-битное число, называемое селектором. В процессорах Intel предусмотрено шесть 16-битных регистров — CS, DS, ES, FS, GS, SS , где хранятся селекторы. (Регистры FS и GS отсутствовали в 8086, но появились уже в 80286.) Это означает, что в любой момент можно изменить параметры, записанные в этих регистрах.
В отличие от DS, ES, GS, FS, которые называются регистрами сегментов данных, CS и SS отвечают за сегменты двух особенных типов – сегмент кода и сегмент стека. Первый содержит программу, исполняющуюся в данный момент, следовательно, запись нового селектора в этот регистр приводит к тому, что далее будет исполнена не следующая по тексту программы команда, а команда из кода, находящегося в другом сегменте, с тем же смещением. Смещение очередной выполняемой команды всегда хранится в специальном регистре EIP (указатель инструкции, 16-битная форма IP), запись в который так же приведет к тому, что далее будет исполнена какая-нибудь другая команда. На самом деле все команды передачи управления – перехода, условного перехода, цикла, вызова подпрограммы и т.п. – и осуществляют эту самую запись в CS и EIP.
2.6. Регистр флагов.
Еще один важный регистр, использующийся при выполнении большинства команд, — регистр флагов. Как и раньше, его младшие 16 бит, представлявшие собой весь этот регистр до процессора 80386, называются FLAGS. В EFLAGS каждый бит является флагом, то есть устанавливается в 1 при определенных условиях или установка его в 1 изменяет поведение процессора. Все флаги, расположенные в старшем слове регистра, имеют отношение к управлению защищенным режимом, поэтому здесь рассмотрен только регистр FLAGS (см. рис. 6):

Рис. 6. Регистр флагов FLAGS.
CF – флаг переноса. Устанавливается в 1, если результат предыдущей операции не уместился в приемнике и произошел перенос из старшего бита или если требуется заем (при вычитании), в противном случае – в 0. Например, после сложения слова 0 FFFFh и 1, если регистр, в который надо поместить результат, – слово, в него будет записано 0000 h и флаг CF = 1.
PF – флаг четности. Устанавливается в 1, если младший байт результата предыдущей команды содержит четное число битов, равных 1, и в 0, если нечетное. Это не то же самое, что делимость на два. Число делится на два без остатка, если его самый младший бит равен нулю, и не делится, когда он равен 1.
AF – флаг полупереноса или вспомогательного переноса. Устанавливается в 1, если в результате предыдущей операции произошел перенос (или заем) из третьего бита в четвертый. Этот флаг используется автоматически командами двоично-десятичной коррекции.
ZF – флаг нуля. Устанавливается в 1, если результат предыдущей команды – ноль.
SF – флаг знака. Он всегда равен старшему биту результата.
TF – флаг ловушки. Он был предусмотрен для работы отладчиков, не использующих защищенный режим. Установка его в 1 приводит к тому, что после выполнения каждой программной команды управление временно передается отладчику.
IF – флаг прерываний. Сброс этого флага в 0 приводит к тому, что процессор перестает обрабатывать прерывания от внешних устройств. Обычно его сбрасывают на короткое время для выполнения критических участков кода.
DF – флаг направления. Он контролирует поведение команд обработки строк: когда он установлен в 1, строки обрабатываются в сторону уменьшения адресов, когда DF =0 – наоборот.
OF – флаг переполнения. Он устанавливается в 1, если результат предыдущей арифметической операции над числами со знаком выходит за допустимые для них пределы. Например, если при сложении двух положительных чисел получается число со старшим битом, равным единице, то есть отрицательное, и наоборот.
Флаги IOPL (уровень привилегий ввода-вывода) и NT (вложенная задача) применяются в защищенном режиме.
2.7. Цикл выполнения команды
Программа состоит из машинных команд. Программа загружается в оперативную память компьютера. Затем программа начинает выполняться, то есть процессор выполняет машинные команды в той последовательности, в какой они записаны в программе.
Для того чтобы процессор знал, какую команду нужно выполнять в определённый момент, существует счётчик команд – специальный регистр, в котором хранится адрес команды, которая должна быть выполнена после выполнения текущей команды. То есть при запуске программы в этом регистре хранится адрес первой команды. В процессорах Intel в качестве счётчика команд (его ещё называют указатель команды) используется регистр EIP (или IP в 16-разрядных программах).
Счётчик команд работает со сверхоперативной памятью, которая находится внутри процессора. Эта память носит название очередь команд, куда помещается одна или несколько команд непосредственно перед их выполнением. То есть в счётчике команд хранится адрес команды в очереди команд, а не адрес оперативной памяти.
Цикл выполнения команды – это последовательность действий, которая совершается процессором при выполнении одной машинной команды. При выполнении каждой машинной команды процессор должен выполнить как минимум три действия: выборку, декодирование и выполнение. Если в команде используется операнд, расположенный в оперативной памяти, то процессору придётся выполнить ещё две операции: выборку операнда из памяти и запись результата в память. Ниже описаны эти пять операций.
- Выборка команды . Блок управления извлекает команду из памяти (из очереди команд), копирует её во внутреннюю память процессора и увеличивает значение счётчика команд на длину этой команды (разные команды могут иметь разный размер).
- Декодирование команды . Блок управления определяет тип выполняемой команды, пересылает указанные в ней операнды в АЛУ и генерирует электрические сигналы управления АЛУ, которые соответствуют типу выполняемой операции.
- Выборка операндов . Если в команде используется операнд, расположенный в оперативной памяти, то блок управления начинает операцию по его выборке из памяти.
- Выполнение команды . АЛУ выполняет указанную в команде операцию, сохраняет полученный результат в заданном месте и обновляет состояние флагов, по значению которых программа может судить о результате выполнения команды.
- Запись результата в память . Если результат выполнения команды должен быть сохранён в памяти, блок управления начинает операцию сохранения данных в памяти.
Суммируем полученные знания и составим цикл выполнения команды:
- Выбрать из очереди команд команду, на которую указывает счётчик команд.
- Определить адрес следующей команды в очереди команд и записать адрес следующей команды в счётчик команд.
- Декодировать команду.
- Если в команде есть операнды, находящиеся в памяти, то выбрать операнды.
- Выполнить команду и установить флаги.
- Записать результат в память (по необходимости).
- Начать выполнение следующей команды с п.1.
Это упрощённый цикл выполнения команды. К тому же действия могут отличаться в зависимости от процессора. Однако это даёт общее представление о том, как процессор выполняет одну машинную команду, а значит и программу в целом.
Из чего состоит центральный процессор?
Центральный процессор часто называют «мозгом» компьютера, ведь он, как и человеческий мозг, состоит из нескольких частей, собранных воедино для работы над информацией. Среди них есть те, что отвечают за прием информации, ее хранение, обработку и вывод. В этой статье портал TechSpot разбирает все ключевые элементы процессора, за счет которых и работают ваши компьютеры.
Этот текст входит в серию статей, в которых тщательно разбирается работа ключевых компонентов компьютера. Кроме того, если вы заинтересовались темой, рекомендуем ознакомиться с переводами статей серии «Как разрабатываются и создаются процессоры?».

В этой статье будут затронуты как основы работы процессоров, так и более сложные понятия. К сожалению, без некоторой абстрактности не обойтись, но на это есть свои причины. К примеру, если взглянуть на блок питания, можно легко рассмотреть все его части — от конденсаторов до транзисторов, однако в случае с процессорами все не так просто, ведь мы физически не можем разглядеть все микросхемы, а Intel и AMD не спешат делиться подробностями работы своей продукции с широкой публикой. Тем не менее, информация, представленная в статье, применима к подавляющему большинству современных процессоров.
Итак, приступим. Любому вычислительному устройству нужно нечто наподобие центрального процессора. По сути, программист пишет код для выполнения собственных целей, а затем процессор выполняет его для получения необходимого результата. Процессор также подключен к другим частям системы, вроде памяти и устройств ввода/вывода, чтобы обеспечить загрузку необходимых данных, но в этой статье мы не будем акцентировать на них внимание.
Фундамент любого процессора: архитектура набора команд
Первое, на что натыкаешься при разборе любого процессора — это на архитектуру набора команд (ISA). Архитектура является чем-то вроде фундамента работы процессора и именно от нее зависит то, как он работает и как все внутренние системы взаимодействуют друг с другом. Существует огромное количество архитектур, но самыми распространенными являются x86 (преимущественно в стационарных компьютерах и ноутбуках) и ARM (в мобильных устройствах и встроенных системах).
Чуть менее распространенными и более нишевыми являются MIPS, RISC-V и PowerPC. Архитектура набора отвечает за ряд основных вещей: какие инструкции процессор может обрабатывать, как он взаимодействует с памятью и кэшем, как задача распределяется по нескольким этапам обработки и др.

Чтобы лучше понять устройство процессора, разберем его элементы в том порядке, по которому выполняются команды. Различные типы инструкций могут следовать разными путями и использовать разные компоненты ЦП, поэтому здесь они будут обобщены, чтобы охватить максимум. Начнем с базового дизайна одноядерных процессоров и постепенно будем переходить к более продвинутым и сложным экземплярам.
Блок управления и исполнительный тракт
Элементы процессора можно разделить на два основных: блок управления (он же — управляющий автомат) и исполнительный тракт (он же — операционный автомат). Говоря простым языком, процессор — это поезд, в котором машинист (управляющий автомат) управляет различными элементами двигателя (операционного автомата).
Исполнительный тракт подобен двигателю и, как следует из названия, это путь, по которому данные передаются при их обработке. Он получает входные данные, обрабатывает их и отправляет в нужное место после завершения операции. Блок управления, в свою очередь, направляет этот поток данных. В зависимости от инструкции, исполнительный тракт будет направлять сигналы к различным компонентам процессора, включать и выключать различные части пути, а также отслеживать состояние всего процессора.
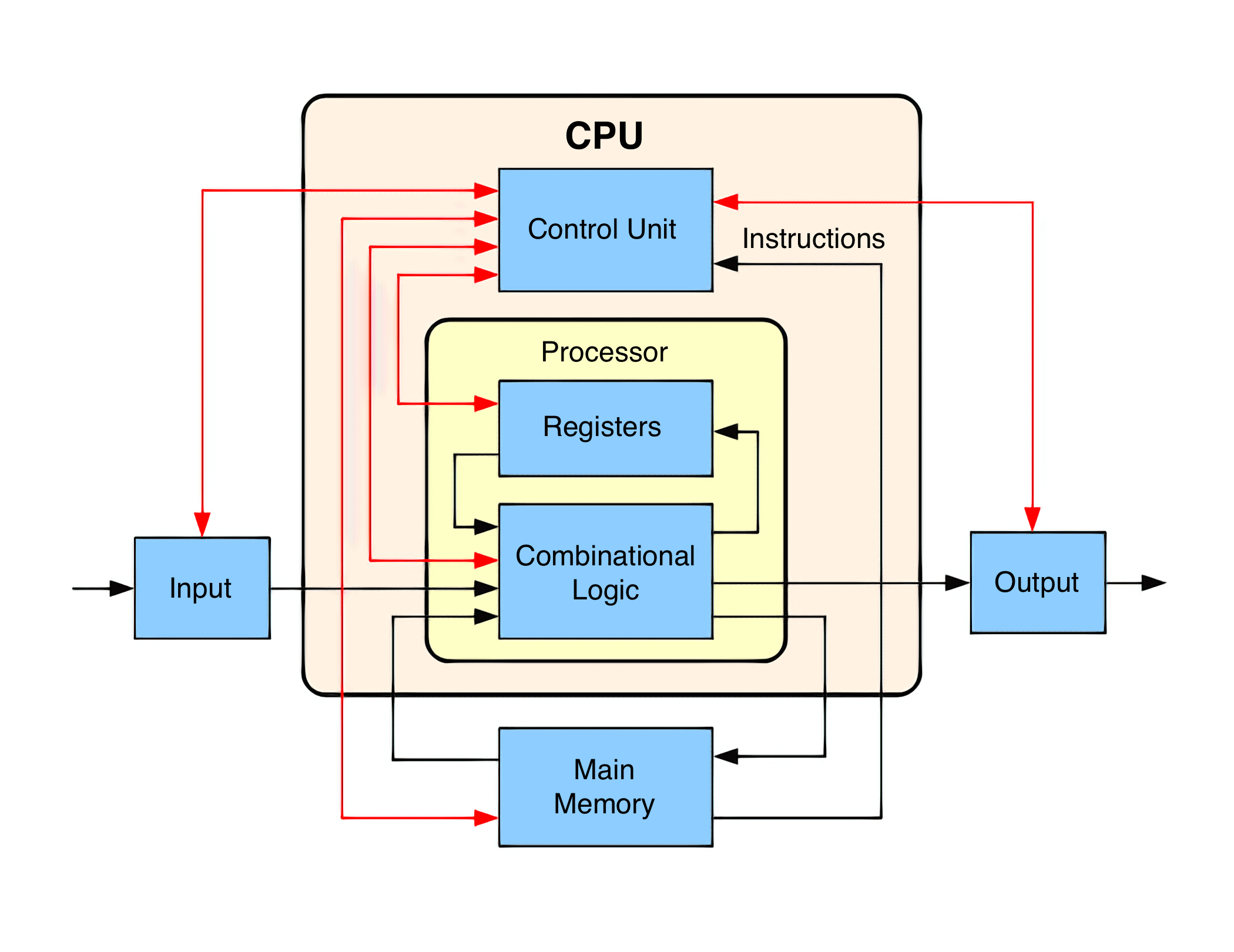
Блок-схема работы базового процессора. Черными линиями отображен поток данных, а красными — поток команд.
Цикл выполнения команд — Выборка
Первое, что должен сделать процессор — определить, какие команды необходимо выполнить следующими, а затем переместить их из памяти в блок управления. Команды создаются компилятором и зависят от архитектуры набора (ISA). Наиболее распространенные типы базовых инструкций (например, «загрузка», «хранение», «сложение», «вычитание» и др.) общие для всех ISA, но существует множество дополнительных, специальных типов команд, уникальных для конкретной архитектуры набора. Блок управления знает, какие сигналы и куда нужно направить для выполнения определенного типа команды.
К примеру, при запуске .exe файла в Windows, код этой программы отправляется в память и процессор получает адрес, с которого начинается первая команда. Процессор всегда поддерживает внутренний реестр, отслеживающий откуда должна будет выполняться следующая команда. Этот реестр называется счетчиком команд.
После того, как процессор определил точку, с которой нужно начинать цикл, происходит перемещение команды из памяти в вышеупомянутый реестр — этот процесс называется выборкой команды. По-хорошему, команда, скорее всего, уже находится в кэше процессора, но этот вопрос будет рассмотрен чуть позже.
Цикл выполнения команд — Декодирование
Когда процессор получает команду, ему нужно точно определить тип этой команды. Данный процесс называется декодированием. Каждая команда обладает особым набором битов, опкодом, который дает возможность процессору распознать ее тип. Примерно по тому же принципу работает распознавание компьютером различных расширений файлов. К примеру, .jpg и .png — форматы изображений, но каждый из них обрабатывает данные по-разному, поэтому компьютеру и нужно точно распознавать их тип.
Стоит отметить, что сложность декодирования может зависеть от того, насколько продвинутой является архитектура набора команд процессора. У архитектуры RISC-V, к примеру, несколько десятков команд, а у x86 — несколько тысяч. У типичного процессора Intel x86 процесс декодирования является одним из сложнейших и занимает огромное количество памяти. Чаще всего процессоры декодируют команды, связанные с памятью, арифметическими вычислениями и переходом.
3 основных типа команд
Команда памяти может представлять собой нечто вроде «прочтите значение из адреса памяти 1234 вместо значения А» или «запишите значение Б в адрес памяти 5678». Арифметические команды имеют вид в духе «добавьте значение А к значению Б и сохраните результат в значении В». Инструкции перехода, в свою очередь, похожи на «выполните этот код, если значение В положительное, или выполните другой код, если значение В отрицательное». Зачастую в программах используется цепочка сразу из нескольких вышеупомянутых примеров, из-за чего конечный результат выглядит примерно так: «добавьте значение адреса памяти 1234 к значению адреса памяти 5678 и сохраните его в адресе памяти 4321, если результат положительный, либо в адрес 8765, если результат отрицательный».
Перед тем, как перейти к выполнению декодированной команды, давайте уделим немного внимания регистрам.
Регистрами называются немногочисленные, но крайне быстрые фрагменты памяти процессора. У 64-битных процессоров каждый из них вмещает 64 бита, а всего их может быть несколько десятков на одно ядро. Регистры используются для хранения используемых в данный момент значений и их можно считать чем-то вроде кэша нулевого уровня. В приведенных выше примерах команд значения А, Б и В будут сохранены именно в регистре.
Арифметико-логическое устройство
Вернемся к этапу выполнения команд. Сразу отметим, что он отличается для всех трех вышеупомянутых типов команд, поэтому давайте рассмотрим каждый их них.
Самыми простыми для понимания являются арифметические команды. Эти команды отправляются в арифметическо-логическое устройство (ALU) для последующей обработки. Устройство представляет собой цепь, которая чаще всего работает с двумя значениями, отмеченными сигналом, и выдает результат.
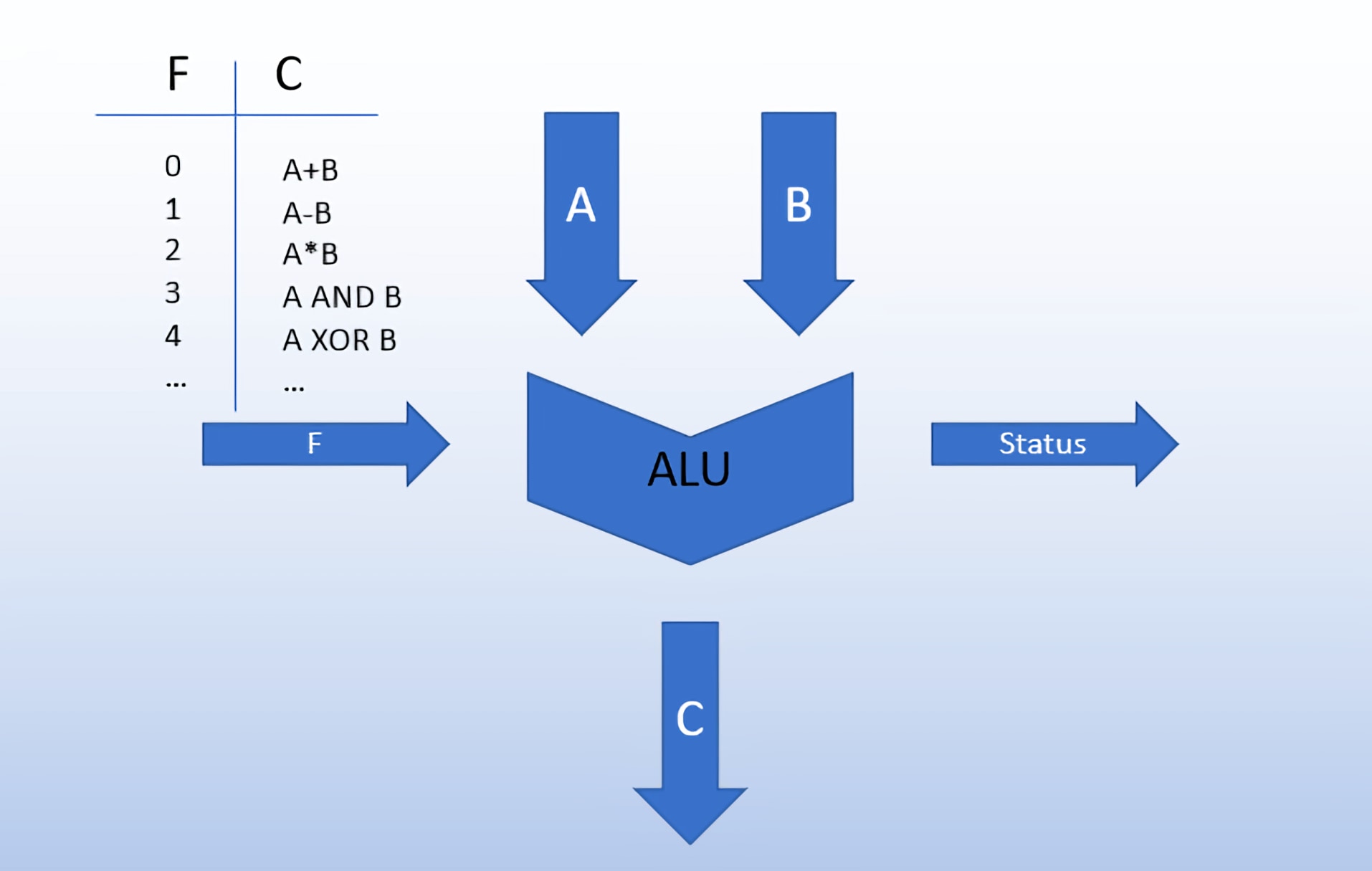
Представьте себе обычный калькулятор. Для любого вычисления вы вводите значения, выбираете необходимую арифметическую операцию и получаете результат. Арифметическо-логическое устройство (ALU) работает по похожему принципу. Тип операции зависит от опкода команды, который управляющий автомат отправляет в ALU и которое в дополнение к базовой арифметике может производить со значениями такие битовые операции, как AND, OR, NOT и XOR. Кроме того, арифметическо-логическое устройство выводит информацию о проведенном вычислении для управляющего автомата (например, оказалось ли оно положительным, отрицательным, равным нулю или вызвало переполнение).
Несмотря на то, что арифметическо-логическое устройство чаще всего связано именно с арифметическими операциями, оно находит свое применение и в инструкциях памяти или перехода. Например, если процессору нужно вычислить адрес памяти, заданный в результате прошлого вычисления, либо в случае необходимости вычислить переход для добавления в счетчик программ, если инструкция того требует (пример: «если предыдущий результат отрицателен, перейти на 20 команд вперед»).
Команды и иерархия памяти
Чтобы лучше понять принцип работы команд, связанных с памятью, стоит обратить внимание на концепцию иерархии памяти — связь между кэшем, оперативной памятью и главным запоминающим устройством. Когда процессор работает с командой памяти, данных о которой у него еще нет в регистре, он будет продвигаться по иерархии памяти, пока не найдет нужную информацию. Большинство современных процессоров имеют три уровня кэша: первый, второй и третий. Сначала процессор проверит наличие необходимых команд в кэше первого уровня — самом маленьком и быстром из всех. Зачастую этот кэш разделен на две части: первая отведена под данные, а вторая — под команды. Помните, команды извлекаются процессором из памяти так же, как и любые другие данные.
Типичный кэш первого уровня может состоять из нескольких сотен килобайт. Если процессор не найдет в нем то, что нужно, то перейдет к проверке кэша второго уровня (размером в несколько мегабайт), а затем — третьего (уже занимающего десятки мегабайт). В случае, если необходимых данных не будет и в кэше третьего уровня, то поиск будет производиться в оперативной памяти, а затем в накопителях. С каждым подобным «шагом», увеличивается не только объем доступных данных, но и задержка.
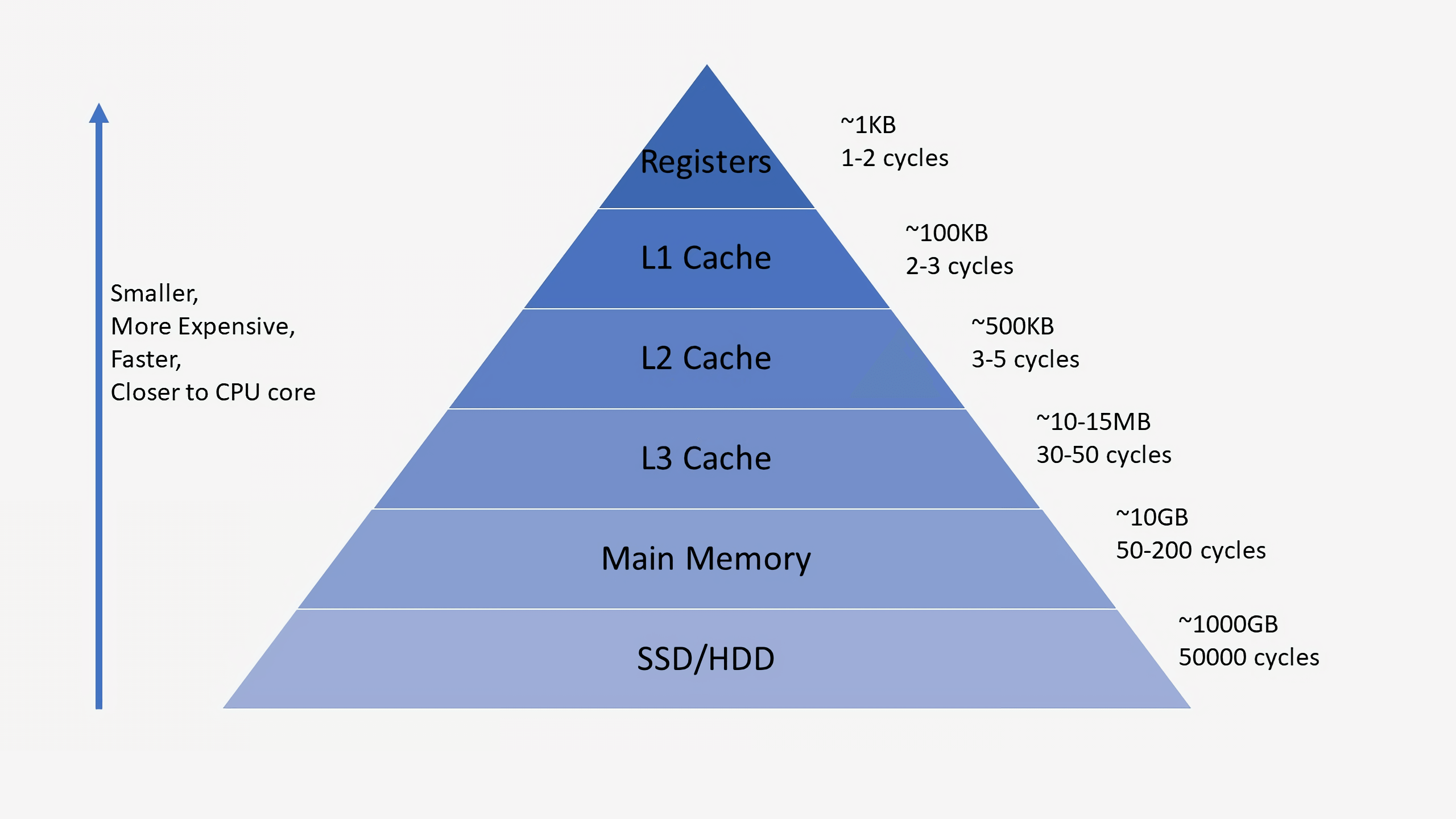
После того, как процессор нашел необходимые данные, он отправляет их вверх по иерархии памяти для сокращения время поиска, на случай, если они понадобятся в дальнейшем. Для справки: процессор может считывать данные во внутреннем регистре всего за один-два цикла, в кэше первого уровня понадобится немногим больше, в кэше второго уровня уже около десяти, а третьего — несколько десятков циклов. Если приходится задействовать память или накопители, то процессору может понадобятся десятки тысяч, а то и миллионы циклов. В зависимости от системы, у каждого ядра процессора может быть собственный кэш первого уровня, общий с другим ядром кэш второго уровня и кэш третьего уровня у группы из четырех или более ядер. Более подробно речь о многоядерных процессорах пойдет позже.
Команды перехода и ветвления
Последняя из трех основных типов команд — это команда ветвления. Команды современных программ постоянно переходят с одного потока процессов на другой, а это значит, что процессор крайне редко выполняет более дюжины смежных команд без перехода. Команды ветвления происходят от элементов программирования, таких как код IF, FOR и RETURN. Все они используются для прерывания выполнения программы или переключения на другую часть кода. Кроме команд ветвления существуют и команды перехода, которые отличаются от первых тем, что они всегда участвуют в процессе выполнения программы.
Кроме обычных команд перехода, существуют и условные переходы, с которыми процессору работать особенно сложно, поскольку он может выполнять несколько инструкций одновременно и конечный результат всей ветки может быть нельзя определить пока не начата работа над выполнением связанных команд.
Чтобы понять, почему процессору трудно работать с условными переходами, стоит обратить внимание на такое понятие, как вычислительный конвейер. Каждый шаг в выполнении какой-либо команды может занимать несколько циклов, а это значит, что арифметико-логическое устройство могло бы простаивать без дела пока происходит выборка команды. Чтобы максимизировать эффективность вычислительной мощности процессора, каждая стадия разделяется на несколько частей — в процессе, который называется вычислительным конвейером (конвейерной обработкой).
Самой простой аналогией будет процесс стирки. Предположим, что у вас достаточно вещей на две полные загрузки стиральной машины, а стирка и сушка каждой партии занимает по часу. Вы вполне можете загрузить в стиральную машину первую партию вещей, а потом переместить на сушилку, а когда они высохнут — заняться второй партией. Это займет четыре часа. Однако, если вы разделите процесс на этапы и начнете стирку второй партии вещей, пока сушится первая, вы сможете выполнить всю работу за три часа. Сокращение времени зависит от количества загружаемых вещей и количества стиральных/сушильных машин. Для выполнения отдельной загрузки в любом случае понадобится два часа, но в приведенном примере накладывание процессов увеличивает общую пропускную способность с 0,5 загрузки/час до 0,75 загрузки в час.
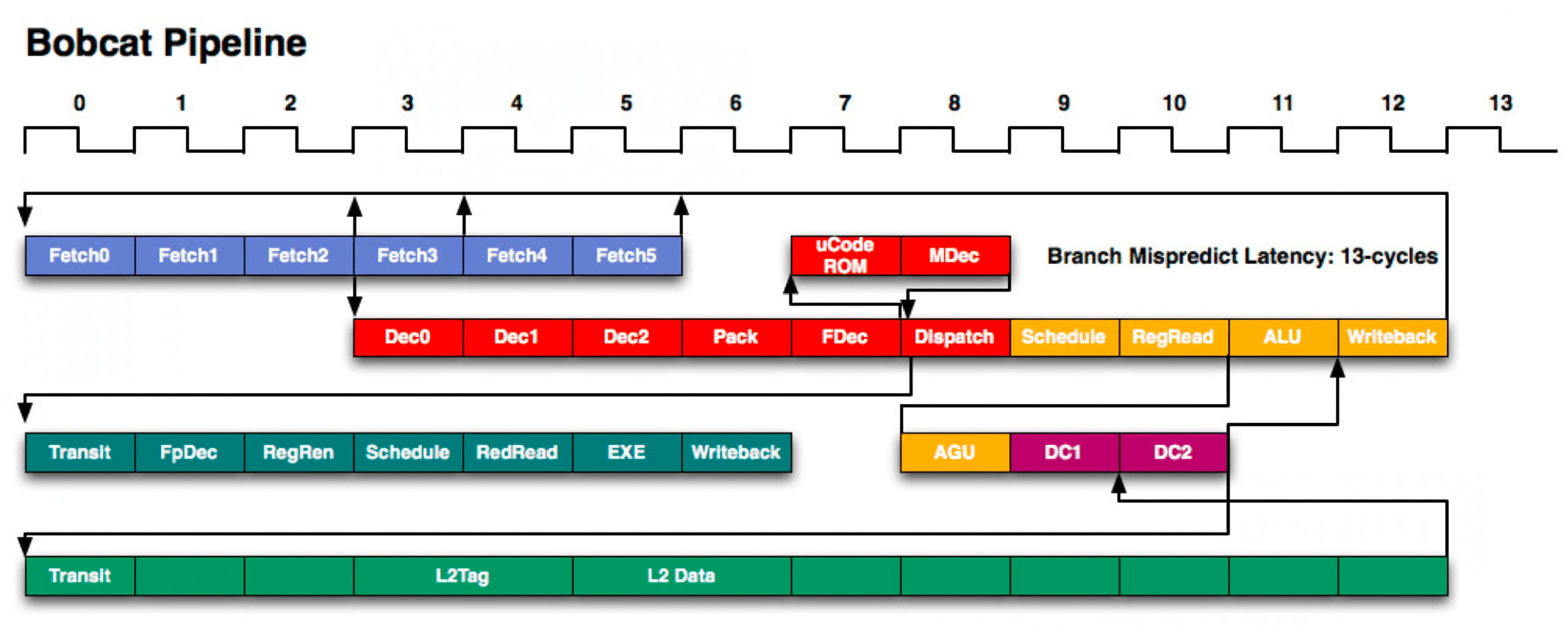
Графическое представление конвейера, используемого в ядрах процессоров AMD Bobcat (2011). Обратите внимание, как много в нем различных элементов и стадий.
Процессоры используют тот же принцип для повышения пропускной способности команд. Конвейеры современных процессоров на архитектуре ARM или x86 могут использовать свыше 20 стадий вычислительного конвейера, а это значит, что ядро процессора одновременно обрабатывает свыше 20 различных команд. Процессоры могут отличаться по разделению этих стадий под различные нужды, но в одном из примеров, принцип работы которого находится в открытом доступе, имеется 4 цикла для выборки, 6 циклов для декодирования, 3 цикла для выполнения команд и 7 циклов для отправки результатов в память.
Возвращаясь к теме, теперь вы можете понять в чем проблема. Если процессор не определил тип команды до десятого цикла, то он начнет работу уже над 9 новыми командами, которые могут оказаться ненужными, если ветка команд уже не работает. Чтобы этого не происходило, процессоры оборудованы сложным механизмом, который называется модулем предсказателем переходов. По принципу работы этот механизм схож с машинным обучением. Детальное описание работы модуля предсказателя переходов — это тема для отдельной статьи, поэтому придется обойтись довольно простым объяснением: данный механизм отслеживает статус предыдущих переходов, чтобы определить, будет ли задействован следующий переход или нет. Современные предсказатели переходов могут обеспечить точность в 95% и выше.
После того, как точно станет известен результат перехода (т.е. завершился конкретный этап на конвейере), счетчик команд обновится и процессор приступит к выполнению следующей операции. Если же результат не совпал с тем, который предугадал предсказатель команд, процессор сбросит все команды, которые начал выполнять по ошибке, и запустит работу с правильной точки.
Внеочередное исполнение
Теперь, когда вы знаете принцип работы трех наиболее распространенных типов команд, давайте уделим внимание более продвинутыми функциям процессоров. Практически все современные модели ЦП фактически исполняют команды не в порядке их получения. Существует такая функция, как внеочередное исполнение, призванная сократить время простоя процессора во время ожидания завершения остальных команд.
Если процессор понимает, что следующей команде необходимы данные, для поиска которых понадобится больше времени, он может изменить порядок команд, начав работу над не связанной командой, пока происходит поиск. Внеочередное исполнение команд — необычайно полезная, но далеко не единственная вспомогательная функция процессора.

Еще одной крайне полезной особенностью процессора является предвыборка. Если засечь время, необходимое для выполнения случайной инструкции от начала и до конца, то можно обнаружить, что большую часть времени занимает доступ к памяти. Блок предварительной выборки — элемент в ЦП, который рассматривает команды, находящиеся в очереди, и определяет, какие данные им потребуются. Если он замечает, что для операции нужны данные, которые еще не находятся в кэше процессора, то он извлечет их из оперативной памяти и в кэш. Отсюда и его название.
Ускорители и будущее процессоров
Еще одна важная функция, которая все чаще появляется в процессорах — ускорители для конкретных задач. Эти ускорители представляют собой небольшие схемы, главная цель которых — как можно быстрее выполнить определенную задачу. Этой задачей может быть шифрование, кодирование данных или машинное обучение.
Конечно, процессор может делать все это самостоятельно, но созданный конкретно для этой цели блок будет намного более эффективен. Наглядным показателем мощностей ускорителей будет сравнение встроенного графического процессора с дискретной видеокартой. Разумеется, процессор может выполнять вычисления, необходимые для обработки графики, но наличие отдельного блока обеспечивает намного более высокую производительность. С ростом числа ускорителей фактическое ядро центрального процессора может занимать всего лишь небольшую часть чипа.
На первом рисунке снизу изображено устройство процессора Intel, выпущенного более десяти лет назад, где большая часть занята ядрами и кешем, а на втором показан гораздо более современный чип от AMD. Как мы видим, во втором случае большая часть кристалла отведена не под ядра, а под другие компоненты.
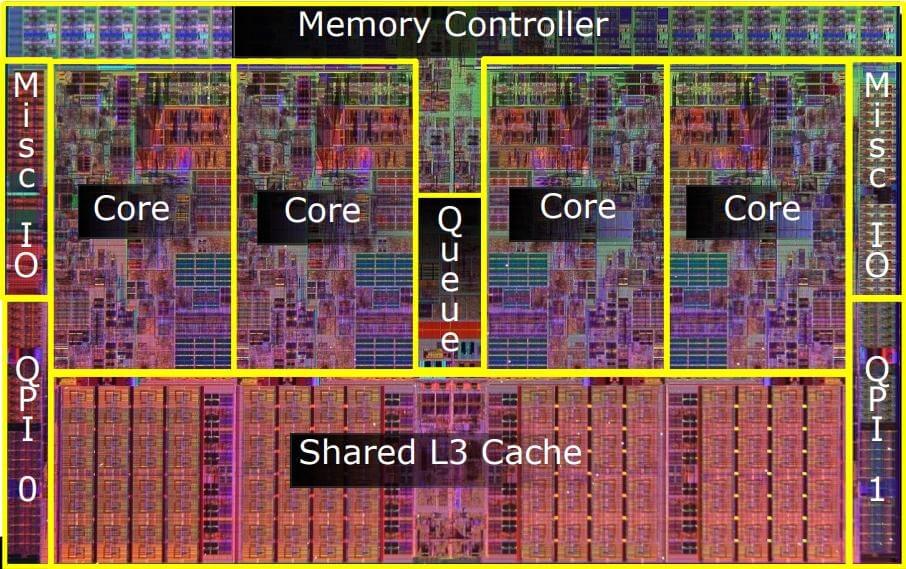
Кристалл процессора Intel первого поколения архитектуры Nehalem. Обратите внимание: ядра и кэш занимают подавляющее часть площади.
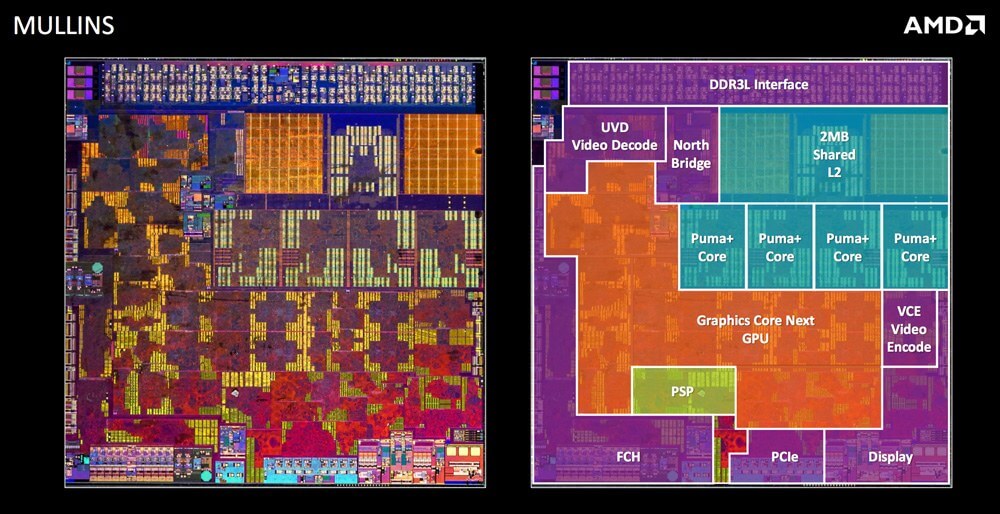
Кристалл системы на чипе от AMD. Много места отведено под ускорители и внешние интерфейсы.
Многоядерность
Последняя особенность процессоров, которая будет рассмотрена в этой статье — то, как можно объединить несколько отдельных процессоров для получения многоядерного. Это не просто объединение нескольких копий одного ядра, ведь как нельзя просто превратить однопоточную программу в многопоточную, так нельзя и провернуть подобное с процессором. Проблема возникает из-за зависимости ядер.
В случае с четырьмя ядрами процессору необходимо отправлять команды в 4 раза быстрее. Также нужно четыре раздельных интерфейса для памяти. Именно из-за наличия нескольких ядер на одном чипе, потенциально работающих с одними и теми же частями данных, возникает проблема слаженности и согласованности их работы. Предположим, если два ядра обрабатывали команду, использующую одни и те же данные, то как процессор определяет, у которого из них правильное значение? А что, если одно ядро модифицировало данные, но они не успели вовремя дойти до второго ядра? Поскольку у них есть отдельные кэши, в которых могут храниться пересекающиеся данные, для устранения возможных конфликтов необходимо использовать сложные алгоритмы и контроллеры.
Чрезвычайно важную роль в многоядерных процессорах играет и точность прогнозирования переходов. Чем больше в процессоре ядер, тем выше вероятность того, что одной из исполняемых команд будет именно команда перехода, способная в любое время изменить общий поток задач.
Как правило, отдельные ядра обрабатывают команды из разных потоков, тем самым снижая зависимость между ядрами. Поэтому, открыв диспетчер задач, вы чаще всего видите, что загружено лишь одно ядро процессора, а другие едва работают — многие программы попросту изначально не предназначены для многопоточности. Кроме того, могут быть определенные случаи, в которых эффективнее использовать только одно ядро процессора, а не тратить ресурсы на попытки разделить команды.
Физическая оболочка процессора
Несмотря на то, что большая часть этой статьи была посвящена сложным механизмам работы архитектуры процессора, не стоит забывать и о том, что все это должно быть создано и работать в виде реального, физического объекта.
Для того, чтобы синхронизировать работу всех компонентов процессора, используется тактовый сигнал. Современные процессоры обычно работают на частотах от 3.0 ГГц до 5.0 ГГц, и за последнее десятилетие ситуация особо не изменилась. При каждом цикле внутри чипа включаются и выключаются миллиарды транзисторов.
Такты важны для того, чтобы обеспечить идеальную работу каждой стадии вычислительного конвейера. Количество команд, обрабатываемых процессором за каждую секунду, зависит именно от них. Частоту можно увеличить путем разгона, сделав чип быстрее, но это в свою очередь повысит энергопотребление и тепловыделение.

Фото: Michael Dziedzic
Тепловыделение — главный враг процессоров. Когда цифровая электроника нагревается, может начаться разрушение микроскопических транзисторов. Это в свою очередь может привести к повреждению чипа, если тепло не отвести. Чтобы этого не произошло, каждый процессор оборудован термораспределителями. Сам кристалл может занимать всего 20% площади процессора, ведь увеличение площади позволяет более равномерно распределять тепло по радиатору. Кроме того, дополнительно увеличивается количество имеющихся ножек процессора (контактов), предназначенных для взаимодействия с другими компонентами компьютера.
На современных процессорах может располагаться свыше тысячи входных и выходных контактов на задней панели. Мобильный чип может быть оснащен всего несколькими сотнями, поскольку большинство вычислительных элементов расположены уже внутри чипа. Независимо от дизайна, около половины из них предназначены для распределения питания, а остальные — для передачи данных с оперативной памяти, чипсета, накопителей, устройств PCIe и др. Высокопроизводительным процессорам, потребляющим сто и более ампер при полной нагрузке, нужны сотни ножек для равномерного распределения тока. Обычно они покрываются золотом для улучшения проводимости. Стоит отметить, что разные производители располагают ножки по-разному во всей своей многочисленной продукции.
Подытожим на примере
Чтобы подвести итоги, кратко рассмотрим архитектуру процессора Intel Core 2. Это было еще в 2006 году, поэтому некоторые детали могут быть устаревшими, но информации о новых разработках отсутствуют в публичном доступе.
На самом верху располагается кэш команд и буфер ассоциативной трансляции. Буфер помогает процессору определить, где в памяти располагаются необходимые команды. Эти инструкции хранятся в кэше команд первого уровня, а после этого отправляются в предекодер, так как из-за сложностей архитектуры x86 декодирование происходит во множество этапов. Сразу же за ними идет предсказатель переходов и предвыборщик кода, которые снижают вероятность возникновения потенциальных проблем со следующими командами.
Далее команды отправляются в очередь команд. Вспомните, как внеочередное исполнение позволяет процессору выбрать именно ту команду, которую практичнее всего выполнить в конкретный момент из очереди текущих инструкций. После того, как процессор определил нужную команду, та декодируется во множество микроопераций. В то время как команда может содержать сложную для ЦП задачу, микрооперации представляют собой детализированные задачи, которые процессору легче интерпретировать.
Затем эти инструкции попадают в таблицу псевдонимов регистров, переупорядочивающий буфер и станцию резервации. Подробно расписать их принцип работы в одном абзаце, увы, не получится, так как это — информация, которую обычно подают на последних курсах технических вузов. Если в двух словах, то все они используются в процессе внеочередного исполнения для управления зависимостями между командами.
На самом деле, у каждого ядра процессора множество арифметическо-логических устройств и портов памяти. Команды отправляются в станцию резервации, пока не освободится устройство или порт. Затем команда обрабатывается с помощью кэша данных первого уровня, а полученный результат сохраняется для дальнейшего использования, после чего процессор может приступать к следующей задаче. На этом все!
Пусть эта статья и не предназначалась для того, чтобы служить исчерпывающим руководством по тому, как работает каждый из процессоров, она должна дать вам базовое представление об их внутренней работе и сложности. К сожалению, о том, как действительно работают современные процессоры, знают лишь работники Intel и AMD, поэтому информация, описанная в этой статье — лишь вершина айсберга, ведь каждый пункт, описанный в тексте — это результат огромного количества исследований и разработок.
Другие материалы по теме
Если вам хочется узнать больше о том, как создаются различные компоненты, описанные в этом тексте, то настоятельно советуем обратить внимание на вторую часть серии статей «Как разрабатываются и создаются процессоры?». Если же вы больше заинтересованы в том, как производятся физические оболочки процессоров, то вам стоит ознакомиться с третьей статьей той же серии.
Источник http://www.av-assembler.ru/asm/afd/asm-cycle-command.htm
Источник https://www.sites.google.com/site/sistprogr/lekcii1/lek2
Источник https://i2hard.ru/publications/24825/